Kalman Filter¤
This example optimizes the parameters of a Kalman-Filter.
This example is available as a Jupyter notebook here.
from types import SimpleNamespace
import diffrax as dfx
import equinox as eqx # https://github.com/patrick-kidger/equinox
import jax.numpy as jnp
import jax.random as jr
import jax.tree_util as jtu
import matplotlib.pyplot as plt
import optax # https://github.com/deepmind/optax
We use Equinox to build the Kalman-Filter implementation and to represent linear, time-invariant systems (LTI systems).
We use Optax for optimisers (Adam etc.)
Problem Formulation¤
Assume that there exists some unknown dynamical system of the form
\(\frac{dx}{dt}(t)= f(x(t), u(t), t)\)
\(y(t) = g(x(t)) + \epsilon(t)\)
where - \(u(t)\) denotes the time-dependent input to the system - \(y(t)\) denotes the time-dependent output / measurement to the system - \(x(t)\) denotes the time-dependent state of the system (which is not directly measureable in general) - \(f,g\) denote the time-dependent dynamics- and measurement-function, respectively - \(\epsilon\) denotes random measurement uncertainty
The goal is to infer \(x\) from \(y\) even though \(f,g,\epsilon\) are unkown.
A Kalman-Filter represents a possible solution.
Info
From Wikipedia:
Kalman filtering, also known as linear quadratic estimation (LQE), is an algorithm that uses a series of measurements observed over time, including statistical noise and other inaccuracies, and produces estimates of unknown variables that tend to be more accurate than those based on a single measurement alone, by estimating a joint probability distribution over the variables for each timeframe. The filter is named after Rudolf E. Kálmán, who was one of the primary developers of its theory.
The algorithm works by a two-phase process. For the prediction phase, the Kalman filter produces estimates of the current state variables, along with their uncertainties. Once the outcome of the next measurement (necessarily corrupted with some error, including random noise) is observed, these estimates are updated using a weighted average, with more weight being given to estimates with greater certainty. The algorithm is recursive. It can operate in real time, using only the present input measurements and the state calculated previously and its uncertainty matrix; no additional past information is required.
For the sake of simplicity, here we assume that the dynamical system takes the form
\(\frac{dx}{dt}(t) = Ax(t) + Bu(t)\)
\(y(t) = Cx(t) + \epsilon(t)\)
where \(A,B,C\) are constant matrices, i.e. the system is linear in its state \(x(t)\) and its input \(u(t)\). Further, the dynamics- and measurement-functions do not depend on time.
Hence, the above represents the general form of (physical) linear, time-invariant systems (LTI systems).
Here we define a container object for LTI systems.
class LTISystem(eqx.Module):
A: jnp.ndarray
B: jnp.ndarray
C: jnp.ndarray
An harmonic oscillator is an LTI system, this function returns such an LTI system.
def harmonic_oscillator(damping: float = 0.0, time_scaling: float = 1.0) -> LTISystem:
A = jnp.array([[0.0, time_scaling], [-time_scaling, -2 * damping]])
B = jnp.array([[0.0], [1.0]])
C = jnp.array([[0.0, 1.0]])
return LTISystem(A, B, C)
Here we define some utility functions that allow us to simulate LTI systems.
def interpolate_us(ts, us, B):
if us is None:
m = B.shape[-1]
u_t = SimpleNamespace(evaluate=lambda t: jnp.zeros((m,)))
else:
u_t = dfx.LinearInterpolation(ts=ts, ys=us)
return u_t
def diffeqsolve(
rhs,
ts: jnp.ndarray,
y0: jnp.ndarray,
solver: dfx.AbstractSolver = dfx.Dopri5(),
stepsize_controller: dfx.AbstractStepSizeController = dfx.ConstantStepSize(),
dt0: float = 0.01,
) -> jnp.ndarray:
return dfx.diffeqsolve(
dfx.ODETerm(rhs),
solver=solver,
stepsize_controller=stepsize_controller,
t0=ts[0],
t1=ts[-1],
y0=y0,
dt0=dt0,
saveat=dfx.SaveAt(ts=ts),
).ys
def simulate_lti_system(
sys: LTISystem,
y0: jnp.ndarray,
ts: jnp.ndarray,
us: jnp.ndarray | None = None,
std_measurement_noise: float = 0.0,
key=jr.PRNGKey(
1,
),
):
u_t = interpolate_us(ts, us, sys.B)
def rhs(t, y, args):
return sys.A @ y + sys.B @ u_t.evaluate(t)
xs = diffeqsolve(rhs, ts, y0)
# noisy measurements
ys = xs @ sys.C.transpose()
ys = ys + jr.normal(key, shape=ys.shape) * std_measurement_noise
return xs, ys
Here we define the Kalman-Filter.
Note how we use equinox to combine the Kalman-Filter logic in __call__ and the Kalman-Filter parameters \(Q\) , \(R\) in one object.
The matrices \(Q\) and \(R\) must be positive-definite. To ensure that this property always holds, we fit a matrices \(Q'\) and \(R'\) instead, and obtain \(Q\) and \(R\) from their matrix-matrix products. (I.e. \(Q = Q'^T \cdot Q'\), with \(Q'\) square.)
class KalmanFilter(eqx.Module):
"""Continuous-time Kalman Filter
Ref:
[1] Optimal and robust estimation. 2nd edition. Page 154.
https://lewisgroup.uta.edu/ee5322/lectures/CTKalmanFilterNew.pdf
"""
sys: LTISystem
x0: jnp.ndarray
P0: jnp.ndarray
Q_root: jnp.ndarray # "matrix roots" to ensure that Q, R are positive definite
R_root: jnp.ndarray
def __call__(self, ts, ys, us: jnp.ndarray | None = None):
A, B, C = self.sys.A, self.sys.B, self.sys.C
y_t = dfx.LinearInterpolation(ts=ts, ys=ys)
u_t = interpolate_us(ts, us, B)
y0 = (self.x0, self.P0)
def rhs(t, y, args):
x, P = y
# eq 3.22 of Ref [1]
R = self.R_root.T @ self.R_root
K = P @ C.transpose() @ jnp.linalg.inv(R)
# eq 3.21 of Ref [1]
Q = self.Q_root.T @ self.Q_root
dPdt = (
A @ P
+ P @ A.transpose()
+ Q
- P @ C.transpose() @ jnp.linalg.inv(R) @ C @ P
)
# eq 3.23 of Ref [1]
dxdt = A @ x + B @ u_t.evaluate(t) + K @ (y_t.evaluate(t) - C @ x)
return (dxdt, dPdt)
return diffeqsolve(rhs, ts, y0)[0]
Main entry point. Try runnning main().
def main(
# evaluate at these timepoints
ts=jnp.arange(0, 5.0, 0.01),
# system that generates data
sys_true=harmonic_oscillator(0.3),
# initial state of our data generating system
sys_true_x0=jnp.array([1.0, 0.0]),
# standard deviation of measurement noise
sys_true_std_measurement_noise=1.0,
# our model for system `true`, it's not perfect
sys_model=harmonic_oscillator(0.7),
# initial state guess, it's not perfect
sys_model_x0=jnp.array([0.0, 0.0]),
# weighs how much we trust our model of the system
Q_root=jnp.diag(jnp.ones((2,))) * 0.1,
# weighs how much we trust in the measurements of the system
R_root=jnp.diag(jnp.ones((1,))),
# weighs how much we trust our initial guess
P0=jnp.diag(jnp.ones((2,))) * 10.0,
plot=True,
n_gradient_steps=0,
print_every=10,
):
xs, ys = simulate_lti_system(
sys_true, sys_true_x0, ts, std_measurement_noise=sys_true_std_measurement_noise
)
kmf = KalmanFilter(sys_model, sys_model_x0, P0, Q_root, R_root)
initial_Q = kmf.Q_root.T @ kmf.Q_root
initial_R = kmf.R_root.T @ kmf.R_root
print(f"Initial Q: \n{initial_Q}\n Initial R: \n{initial_R}")
# gradients should only be able to change Q/R parameters
# *not* the model (well at least not in this example :)
filter_spec = jtu.tree_map(lambda arr: False, kmf)
filter_spec = eqx.tree_at(
lambda tree: (tree.Q_root, tree.R_root), filter_spec, replace=(True, True)
)
opt = optax.adam(1e-2)
opt_state = opt.init(kmf)
@eqx.filter_value_and_grad
def loss_fn(dynamic_kmf, static_kmf, ts, ys, xs):
kmf = eqx.combine(dynamic_kmf, static_kmf)
xhats = kmf(ts, ys)
return jnp.mean((xs - xhats) ** 2)
@eqx.filter_jit
def make_step(kmf, opt_state, ts, ys, xs):
dynamic_kmf, static_kmf = eqx.partition(kmf, filter_spec)
value, grads = loss_fn(dynamic_kmf, static_kmf, ts, ys, xs)
updates, opt_state = opt.update(grads, opt_state)
kmf = eqx.apply_updates(kmf, updates)
return value, kmf, opt_state
for step in range(n_gradient_steps):
value, kmf, opt_state = make_step(kmf, opt_state, ts, ys, xs)
if step % print_every == 0:
print("Current MSE: ", value)
final_Q = kmf.Q_root.T @ kmf.Q_root
final_R = kmf.R_root.T @ kmf.R_root
print(f"Final Q: \n{final_Q}\n Final R: \n{final_R}")
if plot:
xhats = kmf(ts, ys)
plt.plot(ts, xs[:, 0], label="true position", color="orange")
plt.plot(
ts,
xhats[:, 0],
label="estimated position",
color="orange",
linestyle="dashed",
)
plt.plot(ts, xs[:, 1], label="true velocity", color="blue")
plt.plot(
ts,
xhats[:, 1],
label="estimated velocity",
color="blue",
linestyle="dashed",
)
plt.xlabel("time")
plt.ylabel("position / velocity")
plt.grid()
plt.legend()
plt.title("Kalman-Filter optimization w.r.t Q/R")
main(n_gradient_steps=0)
Initial Q:
[[0.01 0. ]
[0. 0.01]]
Initial R:
[[1.]]
Final Q:
[[0.01 0. ]
[0. 0.01]]
Final R:
[[1.]]
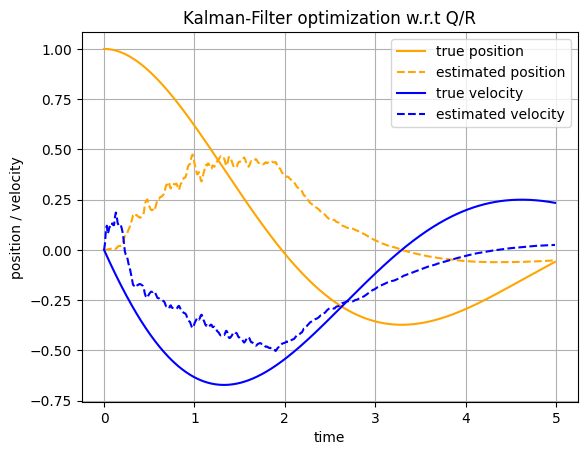
main(n_gradient_steps=100)
Initial Q:
[[0.01 0. ]
[0. 0.01]]
Initial R:
[[1.]]
Current MSE: 0.10384126
Current MSE: 0.09865191
Current MSE: 0.09227132
Current MSE: 0.084715255
Current MSE: 0.07713968
Current MSE: 0.07112989
Current MSE: 0.06693094
Current MSE: 0.0629013
Current MSE: 0.05890039
Current MSE: 0.055452403
Final Q:
[[0.00766012 0.11305381]
[0.11305381 3.1212628 ]]
Final R:
[[0.19311023]]
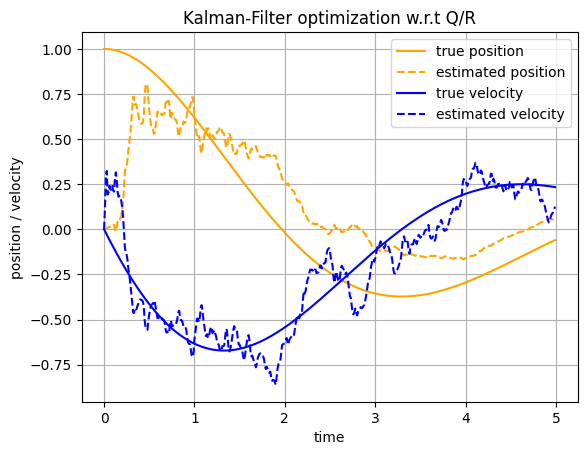
We can see that the MSE is smaller after optimization.
After optimization we trust the measurements more as there is a significant modeling error.
We can observe this nicely through the added noise in our state estimate. Recall that the measurements are noisy after all.